Why Clickhouse is the Next Database you Should Explore
Previously, the Online analytical processing (OLAP) databases were only available as proprietary software offerings like Greenplum, Vertica, Teradata, Paraccel, etc. At that time, it’s very costly to deploy the OLAP databases, and only companies with huge budgets have access to them. Small organizations won’t get a chance to use OLAP databases. Well, things have changed now.
What is Clickhouse
Clickhouse is a fast open-source column-oriented OLAP database management system developed by Yandex for its Yandex.Metrica web analytics service, similar to Google Analytics. It’s built to handle trillions of rows and petabytes of data in mind and perform analytical queries at speed.
Update Sep 2021: Clickhouse Inc spun out of Yandex and recently received $50M Series A funding led by Index Ventures and Benchmark with participation by Yandex N.V. and others.
Clickhouse and OLAP databases are generally used to answer business questions like “How many people visited www.fadhil-blog.dev yesterday coming from Malaysia and using Google Chrome browser?”. The traditional Online Transaction Processing (OLTP) database would take minutes or even hours to process such a query, depending on the dataset size. With the OLAP database, you can get the result in milliseconds. The vast speed difference between OLTP and OLAP is because of the nature of the database itself, column-oriented database vs. row-oriented database.
What is a column-oriented database#
Imagine you have data like below:
----------------------------------------------
| timestamp | domain | visit |
----------------------------------------------
| 2021-09-05 12:00 | fadhil-blog.dev | 20 |
| 2021-09-05 12:00 | medium.com | 300 |
| 2021-09-05 12:01 | fadhil-blog.dev | 15 |
| 2021-09-05 12:02 | fadhil-blog.dev | 21 |
----------------------------------------------
When you’re storing the data in a row-oriented OLTP database like PostgreSQL & MySQL, the data will be logically stored like below:
rowX -> column1, column2, column3;example:
row1 -> 2021-09-05 12:00, fadhil-blog.dev, 20;
row2 -> 2021-09-05 12:00, medium.com, 300;
row3 -> 2021-09-05 12:01, fadhil-blog.dev, 15;
row4 -> 2021-09-05 12:02, fadhil-blog.dev, 21;
The data for each column in a row is written next to each other. This makes the data lookup for individual rows fast. The data update and deletion operations are also fast as you can update or delete rows quickly by theoretically remove that 1 line. But when you’re summing up a group of rows for example the number of visits for fadhil-blog.dev, the database needs to read each row one by one, get the relevant column (and discard the irrelevant columns), then only sum up the total. This is a waste of IO operations, and it is costly, thus reflecting the longer processing time for this query.
However, in column-oriented, the data will be stored like below:
columnX -> row1:id, row2:id, row3:idexample:
timestamp column -> 2021-09-05 12:00:001,2021-09-05 12:00:002,2021-09-05 12:01:003,2021-09-05 12:02:004;
domain column -> fadhil-blog.dev:001,medium.com:002,fadhil-blog.dev:003,fadhil-blog.dev:004;
visit column -> 20:001,300:002,15:003,21:004;
Notice that the data for each row in a column are stored side by side. If you are summing up the number of visits for www.fadhil-blog.dev site, the database first need to look for id for fadhil-blog.dev from domain column, fetch the visit data column for relevant id retrieved and finally sum them up. The database doesn’t need to run many expensive I/O operations to retrieve the whole row, as it only gets the relevant columns in the first place. This is the crucial reason why the column-oriented database is so robust for this query
My explanation is greatly simplified. I recommend you watch this video to understand further how it works and the pros and cons of each.
Why Clickhouse is a game-changer
The primary purposes of Clickhouse or OLAP databases in general but not limited to:
- Data analytics
- Data mining
- Business intelligence
- Log Analysis
By right, you can actually do these analyses in the OLTP database. Common optimization techniques used in the OLTP database are materialized views, multiple writes to multiple timeframe tables, aggregating & rolling up the data into hourly and daily tables periodically using cronjob, use counter increment and decrement (commonly seen in Firebase community), etc. These techniques work for most organizations but, they are not flexible. Imagine you’re an e-commerce vendor, and you’re storing sales records in your database table sales. In order to speed up your analysis, you’re aggregating (using whichever technique I mentioned earlier) the total sales in the table totalSalesDaily with columns date, totalSales. You can easily query average sales made each day or the sum of sales throughout the year from totalSalesDaily table. But, you can’t quickly drill down your database and looking for things like what hour the users are active buying on the site (because the finest granularity is daily), which product is the most popular, etc. Of course, you can query your sales table with raw data, but it would take minutes or hours, and that’s a big no.
This is where Clickhouse comes in. With Clickhouse, you can store the raw data in your database and do the drill-down analysis quickly and flexibly. Nevertheless, you can insert virtually any data into the database. Some companies like Cloudflare, Mux, Plausible, GraphCDN, and Panelbear ingest and store traffic data in Clickhouse and present the report to the user in their dashboard. The Hotel Network is using Clickhouse to store, analyze and give bookings insight to their customers. Percona is using Clickhouse to store and analyze the database performance metrics. You can read more about Clickhouse adopters.
When NOT to Use Clickhouse
You should NEVER use Clickhouse as a replacement for your relational database. Clickhouse is not built to handle row updates and deletions efficiently. Clickhouse should complement your OLTP database instead of replacing them.
This may not apply to everyone but, you should also avoid using Clickhouse as a copy of your OLTP databases. Even though you can technically do so by streaming the data changes from your transactional database to Clickhouse, it’s a best practice to use Clickhouse as the single source of truth for your data and not as the mirror of your OLTP database. Anyway, it depends on your situation.
The Good Parts of Clickhouse
You’re in good company#
When evaluating open-source software, it’s essential to make sure they’re well maintained. You don’t want to adopt a software/technology, but after several years, the project went to the graveyard. It’s not uncommon for such a situation to happen in the open-source world. One good indication of a healthy open-source project is when Internet giants adopt the project. This is because they usually make a lot of considerations before deciding to use the software because it’s very costly for them to change or migrate to another software stack in the future if they made a wrong choice.
Clickhouse is used by Cloudflare, Bloomberg, eBay, Spotify, CERN, and 100s more companies in production. Yandex, for example, has multiple Clickhouse clusters with data of over 120 trillion rows and worth over 100 PiB. This shows how serious the companies are in adopting this software.
Lightning-fast queries#
According to Marko Medojevic, Clickhouse is about 260x faster than MySQL on an analytical query on a dataset with 11M records. However, this is not an apple-to-apple comparison as MySQL is an OLTP database while Clickhouse is an OLAP database, but this demonstrates where the OLAP database shines.
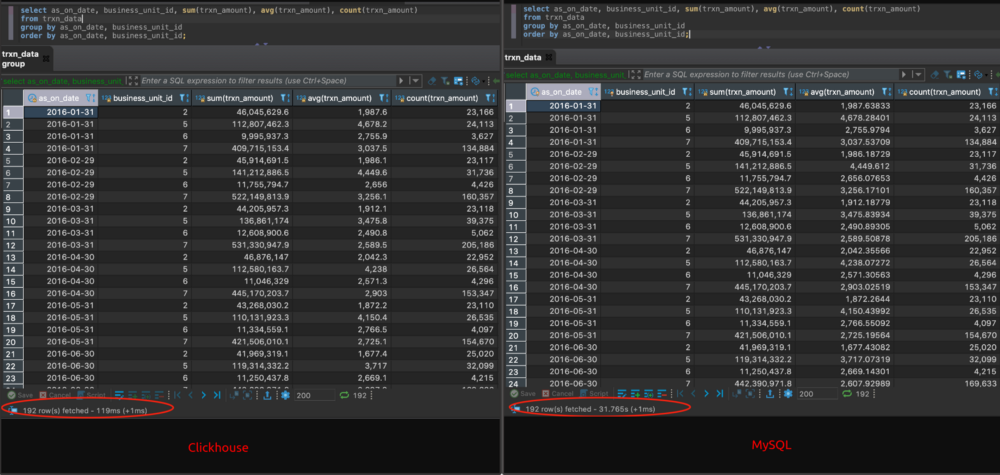
The extreme performance achieved by Clickhouse comes from its unique database engine, MergeTree. Clickhouse is built to exploit all the hardware resources available to give maximum query speed.
For apple-to-apple comparison, Mark Litwintschik is benchmarking various OLAP databases available in the market. From his benchmark test result, Clickhouse is the fastest open source OLAP database. BrytlytDB, OmniSci (previously known as MapD), and kdb+ are commercial databases that perform faster than Clickhouse. Even so, both BrytlytDB and OmniSci use GPUs to accelerate their calculation, while Clickhouse only uses commodity hardware.
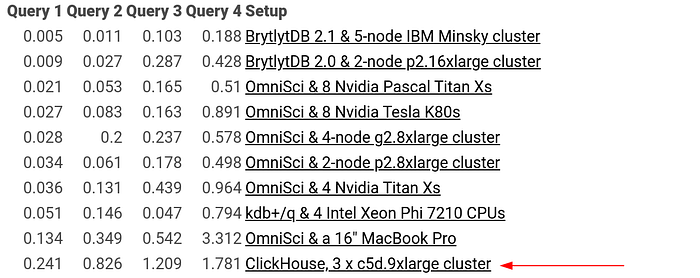
Summary of the 1.1 Billion Taxi Rides Benchmarks
Small index (Sparse index)#
Everyone knows the key to fast data lookup in the database is the index. The indexes are best kept in memory for fast access. In the OLTP database, the indexes are usually stored in B-Tree or B-Tree+ data structures like below.

Courtesy of Javatpoint
This works well for OLTP databases as the primary keys are essential in their nature. In the OLTP database, you are usually querying the database by its ID, for example, query SELECT username, date_of_birth, email FROM user WHERE id = 1234 or query like UPDATE user SET email = "fadhil@gmail.com" WHERE id = 1234. It makes sense to store the index in B-Tree as the access patterns are usually by its ID. But, these indexes will not scale well once the data grow to billions of rows and can no longer fit in RAM.
The objective of the sparse index is to ensure that the index always fits in memory, even the data size is enormous. In Clickhouse, the sparse index is constructed like below.
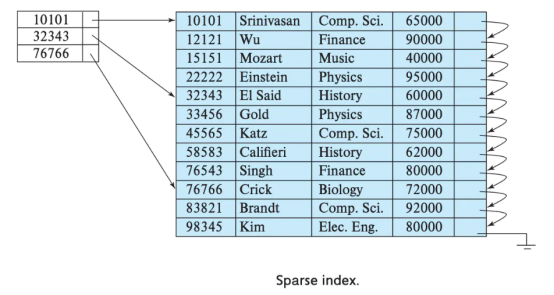
Courtesy of fatalerrors.org
Clickhouse only stores a subset of its index data, and it acts as a ‘checkpoint’ in the large dataset. With this, the index size is relatively small, and it can support huge tables while still able to fit in memory. Imagine queries like SELECT SUM(visit) FROM visit WHERE date BETWEEN '2021-07-01' AND '2021-07-31', it makes sense for the database to keep the index in a sparse index fashion as the access patterns are by a range of date and NOT by ID. That’s why the sparse index is great in the OLAP database. To be frank, the sparse index is terrible for a single row retrieval.
The best data are the data that you can skip
Data Compression#
As the data are stored by column rather than by row, Clickhouse is able to compress the data far better than a row-oriented database. PostHog has seen a 70% reduction in disk space needed to store the same data in PostgreSQL. In Clickhouse, you can specify which data compression codec and compression level for which column in your table. High compression levels are helpful for asymmetric scenarios, like compress once, decompress repeatedly. Higher levels mean better compression, smaller size in disk space, and higher CPU usage.
Data TTL#
It’s not always a good idea to store your data infinitely; otherwise, you’ll run out of disk space at some point. In most cases, you want to set a reasonable data retention period for your data. In Clickhouse, you can set a policy to delete the rows after a certain period. You can easily do so by setting data TTL when creating your table like below:
CREATE TABLE example
(
date DateTime,
a Int
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(date)
ORDER BY d
TTL d + INTERVAL 1 MONTH
The DDL statement above will create a table ’example’ and automatically deletes the data when the ‘date’ is more than one month from the current date.
Drivers/adapters in major programming languages#
Clickhouse community is very active. There are drivers written in Go, Python, Elixir, Ruby, etc. There are also adapters written for frameworks like Ruby on Rails Active Record, Phoenix/Ecto, Django ORM, and many more. That means you can easily connect Clickhouse to your existing system.
Clickhouse also comes with a built-in HTTP interface. If you want to use Clickhouse in your exotic programming language, you can use its HTTP interface directly and call its endpoint directly. In fact, some drivers mentioned above are actually built on this HTTP interface. It also comes with an HTTP keepalive feature, and I believe it supports connection pooling internally.
Horizontal scalability & fault tolerance#
Clickhouse is built with both horizontal scalability and high availability in mind. You can shard your data into multiple nodes & replicate the data into another set of servers. The benefits are:
- You can store data beyond the size of a single server
- Improve the query performance as the request are processed by multiple nodes parallelly
- Improve fault tolerance and avoid single point of failure
Same as in other systems, horizontal scalability and high availability feature doesn’t come for free. The complexity may arise when you’re setting up a cluster, especially a stateful cluster. You may use Clickhouse Kubernetes Operator to set this up if you’re on Kubernetes.
Caveats
Duplicating primary keys#
This might sound weird to you, but yes, Clickhouse supports duplicating primary keys. Depending on your use cases, this might be good or bad for you. If you don’t want duplicate primary keys in your table, you can use the ReplacingMergeTree table engine to clean up and remove duplicating keys in your database automatically. However, remember that a database cleaning/merge operation happens at an unknown time in the background, so you’ll see the duplicating primary keys for some time before they’re cleaned up.
Prefers batch data insertion#
Due to the nature of how the MergeTree engine works, it works best if you insert the data in large batches rather than small frequent insertions. In normal circumstances, Clickhouse can handle thousands of records in a single batch insert operation.
Behind the scene, every insertion in Clickhouse will create a single file part in /var/lib/clickhouse/data/<database/<table>/<sort_key>/. Clickhouse will then merge the parts at an unknown time in the background. If you’re doing a lot of small insertions, there’ll be many parts created in the directory that need to be merged by the engine. That’s why Clickhouse prefers large batch insertion.
You may refer to my other post on how to build a batch worker in Python.
Row update & deletion is expensive#
There is no easy way to update or delete your table rows. Here are a few ways you can update or delete your data rows:
- Use ALTER TABLE command in Clickhouse to update or delete data. They only take effect after the data merging is done at an unknown time in the background. You can’t rely on this command to update/delete the data rows.
- Use the DROP PARTITION command to delete one whole partition
- Use the CollapsingMergeTree table engine for data deletion. The way it works is, when you want to delete a row, you write another row that ‘cancels’ out the existing data
- Use the ReplacingMergeTree table engine for data updates. The way it works is, you write another row with the same ID. However, same as ALTER TABLE command, this only takes effect after the merging job is done in the background at an unknown time.
Even though it has several ways to update or delete data rows, none of them are as convenient as UPDATE table SET x = yor DELETE table WHERE id = x in MySQL. You have to adapt to it.
Special table engines#
Clickhouse unarguably has a lot of table engines that might confuse you at first. Each of them serves its own purpose. For example, when you want to:
- Ingest data from Kafka; you might want to use Kafka special table engine to accept Kafka messages
- Join data between tables; you might want to use Join special table engine to speed up the JOIN operation
- Materialize data; you might want to use Materialized table engine for that
- Replicating data in your cluster; you must use ReplicatedMergeTree table engine for that
- Many more database and table engines
Clickhouse has its own way of doing things. However, you probably don’t need them when you first starting with Clickhouse.
Deploying the database#
The major cloud providers haven’t officially offer managed Clickhouse service yet. The cloud providers that provide managed Clickhouse services are Yandex, Alibaba, and Tencent. If you insist to use managed Clickhouse service in your own VPC in the AWS environment, you can use Altinity.
If you’re just starting up with Clickhouse, it’s okay to use a single-node Clickhouse server for the database. You can use tools like clickhouse-backup to help manage and automate the backup process for you. Apart from that, you’ll need fundamental Linux basics to set up and protect the server (setting up Firewall, setting up a backup cron job, etc.). The complexity may arise when scaling to multiple machines where you’ll need a Zookeeper cluster or Clickhouse Keeper to coordinate multiple database servers. At that point, it made sense to use managed Clickhouse service.
For the record, in June 2020, Plausible was *(I believe they still are) *self-managing their Clickhouse database in a single $80/month DigitalOcean droplet.

Conclusion
I’m sold to this database. Adopting Clickhouse or any OLAP database will open up new possibilities for you and your organization. I highly encourage you to give Clickhouse a try and see how it can benefit your organization. It’s open-source anyway, you can quickly spin up a Clickhouse docker container in your machine with these simple commands:
$ docker run -d --name clickhouse-server --ulimit nofile=262144:262144 -p 8123:8123 -p 9000:9000 yandex/clickhouse-server\
$ docker exec -it clickhouse-server clickhouse-client
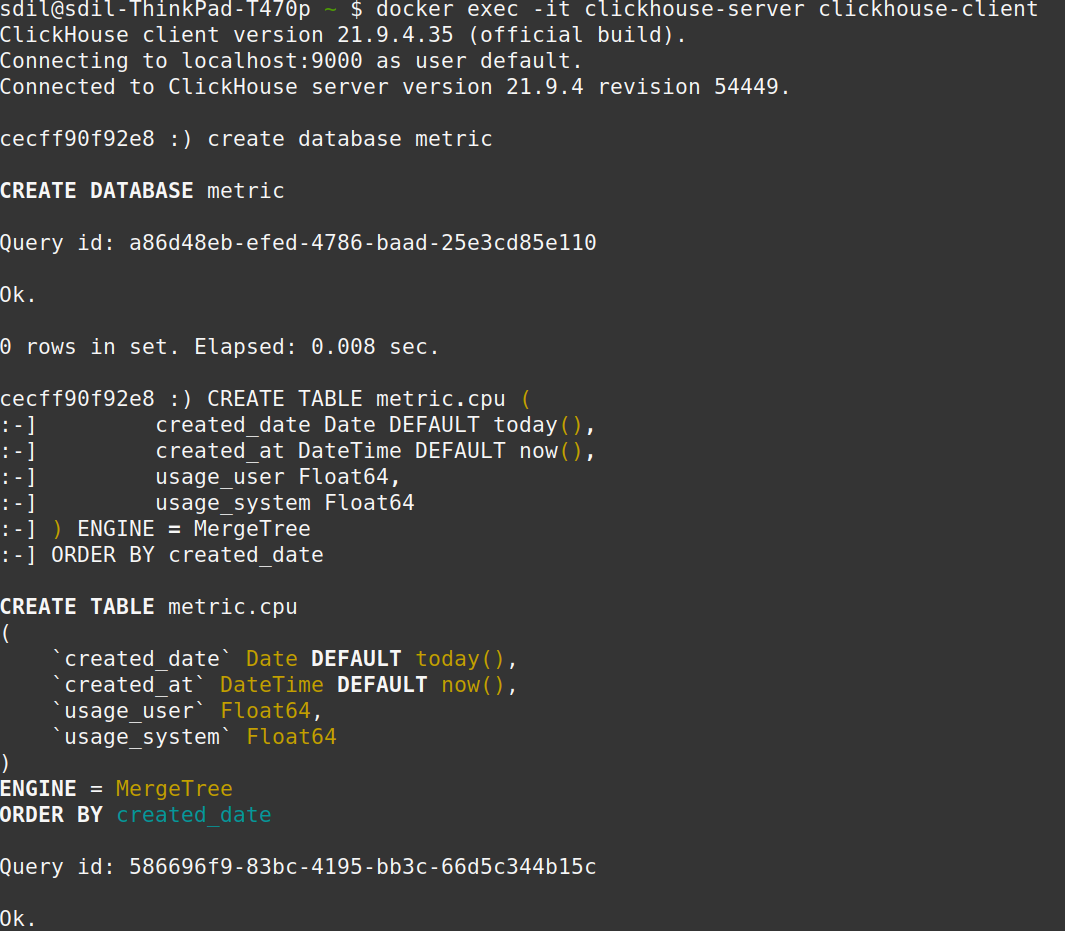
Setting up a database table in Clickhouse container
Ultimately, you should know when to use and when NOT to use the OLAP database. Otherwise, you won’t get its benefit and end up being a technical burden to your organization.