Loosely Coupled Monolith
Microservice architecture is a popular approach to building scalable and maintainable systems. It allows teams to work on different parts of the system independently and deploy them independently. I have an experience working with a large microservice system, and feel the pain of it.
There are many benefits of using a microservice architecture, such as:
- Organization scalability: I think this is the main reason why companies adopts microservice architecture. Each team gets their own autonomy to build their own service however they want.
- Maintainability: Each service is small and focused, making it easier to maintain for each team. Each team doesn’t have to care what’s outside their perimeter.
- Ease of deployment: We can deploy each service independently, allowing us to deploy changes frequently and reduce the risk of introducing bugs.
- Small blast radius: If something goes wrong, it is contained within a single service.
- Clear code ownership: Who owns, maintains and responsible for incidents are properly documented.
However, there are also some challenges to implementing a microservice architecture, such as:
- Deployment complexity: Managing 50 deployments is most likely harder than managing 1 deployment in the eyes of SREs and DevOps engineers.
- Coordination overhead: Testing with many services at once is not easy. Typically, teams mock the service calls between the services. Development is also not easy because you’ll need to spawn multiple services at once to see how they interact end to end. Deployment is the same thing.
- Managing dependencies & contracts between services: There was 1 time where I witnessed teams had incidents where dependent services changed the response structure without notifying the consumer teams.
- Burden to keep up with dependencies in each of the services. With 20 microservices, it could easily takes 1 sprint to update all of deps.
- The availability of the system is defined by its weakest link.
Perhaps we can actually write a monolith that looks like a microservice?
What is loosely coupled monolith?#
I first encountered this concept from CodeOpinion. To me, it’s a different way of writing monolith than most of what the frameworks offer today.
Most frameworks I worked with has some kind of the following characteristics: All database models can be accessed by any controller. Any controller can join tables however they want. In Rails, all the models sits in the same models/ directory and all controllers are free to access any of the models.
In loosely coupled monolith, we will have a different sets of rule:
- Database models sits in the service layer.
- Controller can only access the service layer to get data instead of directly accessing the database models.
- Package import are always inwards. Router can import app package but app package cannot import router.
Example#
I recently implement an API server for my new personal project using Go. This is what the project structure looks like:
.
├── cmd
│ └── web
│ └── main.go
├── internal
│ ├── apps
│ │ ├── services.go
│ │ └── user
│ │ ├── actor.go
│ │ └── user.go
│ ├── managers
│ │ ├── managers.go
│ │ ├── user.go
│ └── workers
│ └── workers.go
├── migrations
│ ├── clickhouse
│ │ └── 20250405232355_create_event_table.sql
│ └── postgres
│ └── 20241119142056_create_user_tabl.sql
├── pkg
│ ├── apiserver
│ │ ├── router.go
│ │ └── routes
│ │ └── user.go
│ ├── infrastructure
│ │ ├── actor
│ │ │ └── goakt.go
│ │ ├── db
│ │ │ ├── clickhouse.go
│ │ │ └── postgres.go
│ │ └── s3
│ │ └── s3.go
│ └── utils
│ └── hash.go
├── Makefile
├── docker-compose.yaml
├── Dockerfile
├── go.mod
├── go.sum
└── integration_tests
└── healthcheck.hurl
*Many of the files are removed for brevity
Data always flows like this:
Router -> Manager -> App -> Database
Each components has their own responsiblities:
- Router: Accepts the request from users, serialize the data into internal data structure and call the manager. Router can be any of API server (JSON, XML, whatever you want), GRPC server or HTML rendered server.
- Manager: Optionally starts a database transaction, and then call the necessary app to perform any operations (eg users.CreateUser)
- App: Actually perform the actions for the operations eg. create database row,call 3rd party API, publish event message, spawn an actor, perform AI magic, etc.
- Database: Persist data. Whichever database does not matter.
In my case, for now, there is no way an app can call another app directly, only managers can them and pass the data between them.
These are examples of each of the components looks like:
// routes/user.go
func (rs RouteService) newUser(c fuego.ContextWithBody[NewUserRequest]) (*UserResponse, error) {
body, err := c.Body()
if err != nil {
// Validate the input
return nil, err
}
u := model.User{
Username: body.Username,
Email: body.Email,
}
result, err := rs.manager.NewUser(c.Context(), u)
if err != nil {
return nil, fuego.HTTPError{
Title: "Failed to create user",
Detail: err.Error(),
Status: http.StatusInternalServerError,
}
}
return &UserResponse{
ID: int(result.ID),
Username: result.Username,
Email: result.Email,
}, nil
}
// managers/user.go
func (m Manager) NewUser(ctx context.Context, user model.User) (*model.User, error) {
tx, err := m.db.BeginTx(ctx, nil)
if err != nil {
return nil, err
}
defer tx.Commit()
result, err := m.services.UserService.CreateUser(ctx, tx, user)
if err != nil {
tx.Rollback()
return nil, err
}
// Schedule a background job to send welcome email to the user
return result, nil
}
// apps/user.go
func (s UserService) CreateUser(ctx context.Context, dbtx qrm.Queryable, user model.User) (*model.User, error) {
slog.Info("User Service: creating a new user")
result := model.User{}
stmt := User.INSERT(User.Username, User.Email).MODEL(user).RETURNING(User.AllColumns)
err = stmt.QueryContext(ctx, dbtx, &result)
if err != nil {
slog.Error("User Service: Error inserting user", "err", err)
return nil, err
}
if err := s.eb.Publish(ctx, &eventbus.Event{
Event: eventbus.EventUserCreated,
Id: int64(userId),
}); err != nil {
slog.Error("Error publishing user created event", "error", err)
}
return &result, nil
}
Notice that, in microservice world, typically the manager would call User microservice which is typically owned by a dedicated team. That call would then involves a DNS query & resolution, data serialization & deserialization, HTTP connection establishment & closing. Sometimes you need to implement rate limiting at each layer, view, controller & data layer, which is a lot of work.
When it comes to loosely-coupled monolith, the manager starts a DB transaction, call internal service like m.services.UserService.CreateUser(ctx, m.db, user) and it’s done. It’s not sexy, I know. m.services.XXX is my service disovery.
I skip writing unit test and I only write integration tests using Hurl. It gives me full confidence that everything works end to end no matter how I change the internal implementation.
Tradeoffs#
The benefits of this approach:
- Testing is easy, no need to mock calls between the services.
- Local development is easy. Only spawn one service and its dependencies and that’s it.
- Deployment is atomic, no need to coordinate deployments between services. In microservice world, there were times where you have to coordinate the deployment where service A has to go out first and service B has to go next. This will never be the case for monolith.
- Each app implementation still has their own (limited) autonomy where they can use any technology or database whichever they want. For example user service can user DynamoDB and AI service can use Postgres. As long as the data struct exposed by the services remain the same, other consuming services does not have to care about the implementation details.
- If you to a single database for the whole monolith, you can use database transaction across services/apps. Database rollback is easy.
- You can make available ‘infrastructure’ packages to all the apps. In my example above, S3, PostgresDB, Goakt and Clickhouse packages are available for any apps to access. I could add ‘infrastructure services’ like Redis cache, Restate, ElasticSearch or any others and all apps could access them.
- Dependencies & runtime update is easy. Updating Go runtime? Just 1 line update in
go.modfile and you’re all set. Updating package dep? Update once and all apps receive the updates. Make sure all the tests are passing. - The service is fast because the data always flows internally. There is no need for data to travel via network and there is no need for data to be serialized and deserialized.
- Each app/service can be owned by a single team, which means you could have a clear code ownership.
- The deployment is super simple, just one homogeneous service to deploy. No need to care about service mesh because of inter-service communication, no need for service discovery setup.
- You don’t need to worry about upstream services are down and implement mitigation techniques like circuit breaker pattern, etc. You can always assume all the apps are running because they are all essentially operate as 1 unit.
- Shared utility code takes effect for the whole app. For example, I implemented OpenTelemetry trace in the
cmd/web/main.goand now the whole app are instrumented and the trace are propagated correctly.
The downsides of this approach are:
- You cannot do database JOINs, which is same to the microservice architecture in order to maintain clear service & data ownership
- Build time could be long especially if you are using compiled language like Go (I believe this is the same for most programming languages)
- Big blast radius: If you’re deploying bad & buggy code, higher chance that it could affect the whole system. A comprehensive & easier testing should help save your face.
- It require strict discipline to make sure that you (or any of your team members) to not break the rules. Otherwise, it would be a mess like any other architecture.
- Rolling out changes could be scary. But with extensive testing, you should be fine.
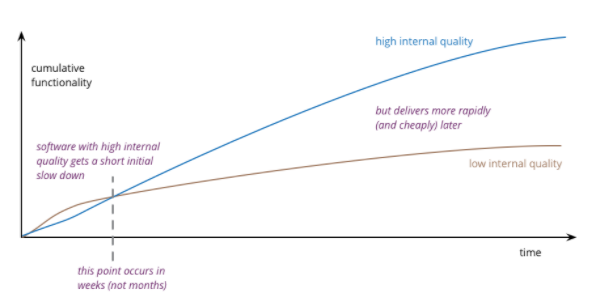
Courtesy of Devgraph.
It takes a longer time to build the foundation since this is not a common architecture compared to Model-View-Controller (MVC) pattern. However, developing a new service is easy, no need a new deployment pipeline, no need for a new subdomain registration, no need for a new Kubernetes deployment manifest etc.
Conclusion#
One thing I learned a lot about this architecture is that, exposing the right interface in your implementation is important no matter what architecture you use. If you expose the interface wrongly, its easy to end up in a ball of mud.
I may not understand it fully, but I’m guessing the term ‘Modular Monolith’ used in Shopify and Github refers to the same architecture. CMIIW.